

A year and two and a half months since his Time magazine doomer article.
No shut downs of large AI training - in fact only expanded. No ceiling on compute power. No multinational agreements to regulate GPU clusters or first strike rogue datacenters.
Just another note in a panic that accomplished nothing.
No shut downs of large AI training
At least the lack of Rationalist suicide bombers running at data centers and shouting ‘Dust specks!’ is encouraging.
why would rationalists do something difficult and scary in real life, when they could be wanking each other off with crank fanfiction and buying
castlesmanor houses for the benefit of the futureconsidering that the more extemist faction is probably homeschooled, i don’t expect that any of them has ochem skills good enough to not die in mysterious fire when cooking device like this
so many stupid ways to die, you wouldn’t believe
It’s also a bunch of brainfarting drivel that could be summarized:
Before we accidentally make an AI capable of posing existential risk to human being safety, perhaps we should find out how to build effective safety measures first.
Or
Read Asimov’s I, Robot. Then note that in our reality, we’ve not yet invented the Three Laws of Robotics.
Before we accidentally make an AI capable of posing existential risk to human being safety, perhaps we should find out how to build effective safety measures first.
You make his position sound way more measured and responsible than it is.
His ‘effective safety measures’ are something like A) solve ethics B) hardcode the result into every AI, I.e. garbage philosophy meets garbage sci-fi.
This guy is going to be very upset when he realizes that there is no absolute morality.
A good chunk of philosophers do believe there are moral facts, but this is less useful for these purposes than one would think
yeah it’s been absolutely hilarious to watch this play out in LLM space. so many prompt configurations and model deployments with so very many string-based rule inputs, meant to be configuring inviolable behaviour, that still get egregiously broken
and afaict none of the dipshits have really seemed to internalise that just maybe their approach isn’t working
He’s talking like it’s 2010. He really must feel like he deserves attention, and it’s not likely fun for him to learn that the actual practitioners have advanced past the need for his philosophical musings. He wanted to be the foundation, but he was scaffolding, and now he’s lining the floors of hamster cages.
He wanted to be the foundation, but he was scaffolding
That’s a good quote, did you come up with that? I for one would be ecstatic to be the scaffolding of a research field.
That’s 100% my weird late-night word choices. You can reuse it for whatever.
I agree with your sentiment, but the wording is careful. Scaffolding is inherently temporary. It only is erected in service of some further goal. I think what I wanted to get across is that Yud’s philosophical world was never going to be a permanent addition to any field of science or maths, for lack of any scientific or formal content. It was always a farfetched alternative fueled by science-fiction stories and contingent on a technological path that never came to be.
Maybe an alternative metaphor is that Yud wanted to develop a new kind of solar panel by reinventing electrodynamics and started by putting his ladder against his siding and climbing up to his roof to call the aliens down to reveal their secrets. A decade later, the ladder sits fallen and moss-covered, but Yud is still up there, trapped by his ego, ranting to anybody who will listen and throwing rocks at the contractors installing solar panels on his neighbor’s houses.
Scaffolding is actually useful, he’s completely irrelevant to actual thought about this. However he is unfortunately influential to some silicon valley nonsense.
EY is not a scaffolding, he’s an advertisement slapped on the scaffolding
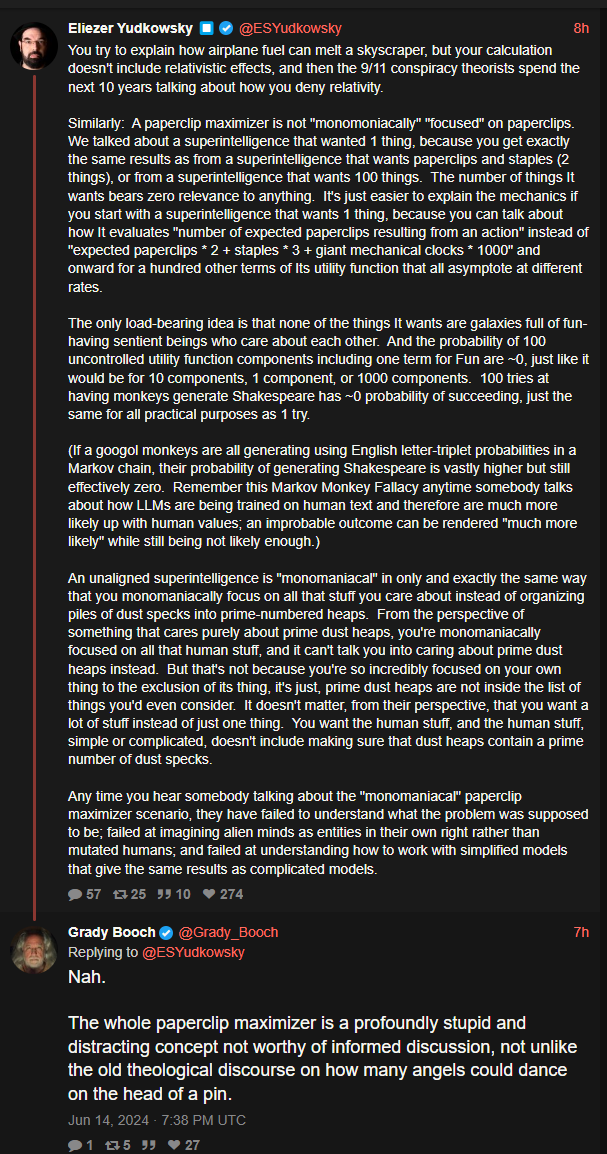
Big Yud: You try to explain how airplane fuel can melt a skyscraper, but your calculation doesn’t include relativistic effects, and then the 9/11 conspiracy theorists spend the next 10 years talking about how you deny relativity.
Similarly: A paperclip maximizer is not “monomoniacally” “focused” on paperclips. We talked about a superintelligence that wanted 1 thing, because you get exactly the same results as from a superintelligence that wants paperclips and staples (2 things), or from a superintelligence that wants 100 things. The number of things It wants bears zero relevance to anything. It’s just easier to explain the mechanics if you start with a superintelligence that wants 1 thing, because you can talk about how It evaluates “number of expected paperclips resulting from an action” instead of “expected paperclips * 2 + staples * 3 + giant mechanical clocks * 1000” and onward for a hundred other terms of Its utility function that all asymptote at different rates.
The only load-bearing idea is that none of the things It wants are galaxies full of fun-having sentient beings who care about each other. And the probability of 100 uncontrolled utility function components including one term for Fun are ~0, just like it would be for 10 components, 1 component, or 1000 components. 100 tries at having monkeys generate Shakespeare has ~0 probability of succeeding, just the same for all practical purposes as 1 try.
(If a googol monkeys are all generating using English letter-triplet probabilities in a Markov chain, their probability of generating Shakespeare is vastly higher but still effectively zero. Remember this Markov Monkey Fallacy anytime somebody talks about how LLMs are being trained on human text and therefore are much more likely up with human values; an improbable outcome can be rendered “much more likely” while still being not likely enough.)
An unaligned superintelligence is “monomaniacal” in only and exactly the same way that you monomaniacally focus on all that stuff you care about instead of organizing piles of dust specks into prime-numbered heaps. From the perspective of something that cares purely about prime dust heaps, you’re monomaniacally focused on all that human stuff, and it can’t talk you into caring about prime dust heaps instead. But that’s not because you’re so incredibly focused on your own thing to the exclusion of its thing, it’s just, prime dust heaps are not inside the list of things you’d even consider. It doesn’t matter, from their perspective, that you want a lot of stuff instead of just one thing. You want the human stuff, and the human stuff, simple or complicated, doesn’t include making sure that dust heaps contain a prime number of dust specks.
Any time you hear somebody talking about the “monomaniacal” paperclip maximizer scenario, they have failed to understand what the problem was supposed to be; failed at imagining alien minds as entities in their own right rather than mutated humans; and failed at understanding how to work with simplified models that give the same results as complicated models
There is a way of seeing the world where you look at a blade of grass and see “a solar-powered self-replicating factory”. I’ve never figured out how to explain how hard a superintelligence can hit us, to someone who does not see from that angle. It’s not just the one fact.
It’s almost as if basing an entire worldview upon a literal reading of metaphors in grade-school science books and whatever Carl Sagan said just after “these edibles ain’t shit” is, I dunno, bad?
There is a way of seeing the world where you look at a blade of grass and see “a solar-powered self-replicating factory”.
this is just “fucking magnets, how do they work?” said different way. both are fascinated with shit that they could understand, but don’t even attempt to. both even built sort of a cult
EY is just ICP for people that don’t do face paint and are high on their own farts
Starting a wall of text with a non sequitur is a bold strategy. I cannot follow his 9/11 logic at all.
Yud lets* us know
2008 called, it wants the pedantry back
2008 called and said we can definitely keep it and it regrets a lot of things
We get it, we just don’t agree with the assumptions made. Also love that he is now broadening the paperclips thing into more things, missing the point of the paperclips thing abstracting from the specific wording of the utility function (because like with disaster prepare people preparing for zombie invasions, the actual incident doesn’t matter that much for the important things you want to test). It is quite dumb, did somebody troll him by saying ‘we will just make the LLM not make paperclips bro?’ and he got broken so much by this that he is replying up his own ass with this talk about alien minds.
e: depressing seeing people congratulate him for a good take. Also “could you please start a podcast”. (A schrodinger’s sneer)
did somebody troll him by saying ‘we will just make the LLM not make paperclips bro?’
rofl, I cannot even begin to fathom all the 2010 era LW posts where peeps were like, “we will just tell the AI to be nice to us uwu” and Yud and his ilk were like “NO DUMMY THAT WOULDNT WORK B.C. X Y Z .” Fast fwd to 2024, the best example we have of an “AI system” turns out to be the blandest, milquetoast yes-man entity due to RLHF (aka, just tell the AI to be nice bruv strat). Worst of all for the rats, no examples of goal seeking behavior or instrumental convergence. It’s almost like the future they conceived on their little blogging site shares very little in common with the real world.
If I were Yud, the best way to salvage this massive L would be to say “back in the day, we could not conceive that you could create a chat bot that was good enough to fool people with its output by compressing the entire internet into what is essentially a massive interpolative database, but ultimately, these systems have very little do with the sort of agentic intelligence that we foresee.”
But this fucking paragraph:
(If a googol monkeys are all generating using English letter-triplet probabilities in a Markov chain, their probability of generating Shakespeare is vastly higher but still effectively zero. Remember this Markov Monkey Fallacy anytime somebody talks about how LLMs are being trained on human text and therefore are much more likely up with human values; an improbable outcome can be rendered “much more likely” while still being not likely enough.)
ah, the sweet, sweet aroma of absolute copium. Don’t believe your eyes and ears people, LLMs have everything to do with AGI and there is a smol bean demon inside the LLMs that is catastrophically misaligned with human values that will soon explode into the super intelligent lizard god the prophets have warned about.
What the fuck any of this mean? What could this be in response to? Was there a bogo deal on $5 words?
I’m one of the lucky 10k who found out what a paperclip maximizer is and it’s dumb as SHIT!

Actually maybe it’s time for me to start grifting too. How’s my first tweet look?
What if ChatGPT derived the anti-life equation and killed every non-black that says the n-word 😟
Paperclip maximizer is a funny concept because we are already living inside of one. The paperclips are monetary value in wealthy people’s stock portfolios.





